在看源码时,可以看到有这么一个方法,从函数名来看,是「找到优先级最高的 root」,但每个应用只有一个 root,那为什么还要去「找」呢?
因为 react 支持多个实例,即支持调用多次 ReactDOM.render。如果他们同时发生更新,也要有个先后关系,这个方法,就是用来从多个实例对应的 root 中,找出最先进行更新的那个 root。
该博客适合对源码有一定了解的同学
- 知道
root表示什么- 知道整个渲染流程的调用链
- 知道批量更新与非批量更新
概述
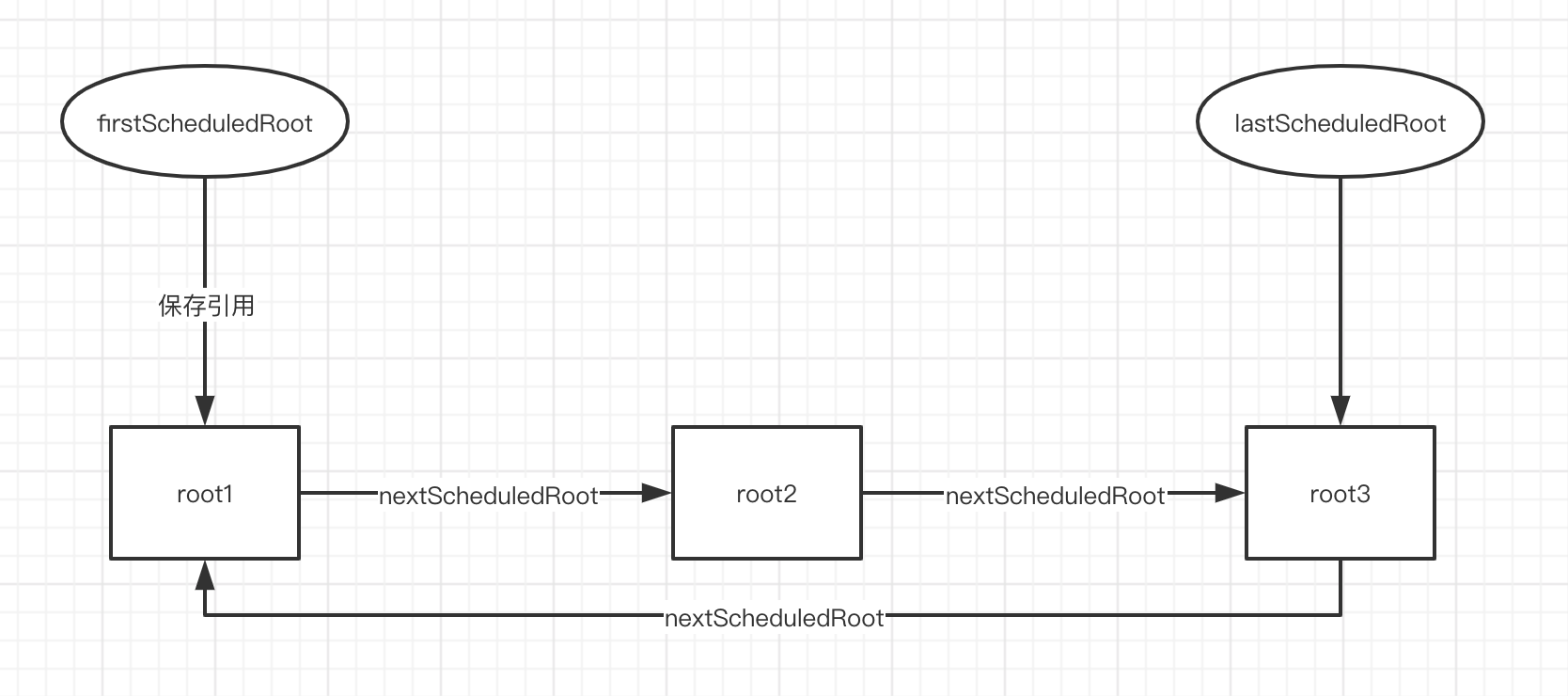
findHighestPriorityRoot 方法其实是一个从「链结构」查找特定节点的算法。root 视为一个节点,root.nextScheduledRoot 指向下一个节点,并且最后一个节点指向第一个节点。
firstScheduledRoot 是该链结构的一个节点,lastScheduledRoot 是该链结构的最后一个节点。每次先从第一个节点开始找。
简单实现
这个算法其实很简单,每个节点上有 value 字段,找到链结构中 value 为最大值的那个节点
1 | class Root { |
1 | const root1 = new Root(200); |
其他影响查找的逻辑
实际的 findHighestPriorityRoot 方法,还有其他逻辑。
1、当 value 为 0 时,该节点就视为无效,需要将该节点从链结构中移除,考虑到这个因素,上面的代码需要进行修改
1 | function findHighestPriorityRoot() { |
2、当 value === 1000 时,不需要再查找,该值必然为最大值。
1 | function findHighestPriorityRoot() { |
对照实际函数
附上 16.8.6 版本该方法实际源码 https://github.com/facebook/react/blob/16.8.6/packages/react-reconciler/src/ReactFiberScheduler.js#L2138
expirationTime 对应 valuehighestPriorityWork 对应 maxValuehighestPriorityRoot 对应 maxValueRootlastScheduledRoot 对应 lastRootfirstScheduledRoot 对应 firstRoot
NoWork === 0Sync === 1000
实际用例
正常业务场景下,只会调用一次 ReactDOM.render,所以不会出现需要「寻找优先级最高的 root」这种情况。不过为了能证实上述的说法,现在运行一个实际用例,断点查看运行过程中那些全局变量的变化
1 | class App1 extends React.Component { |
点击按钮会更新 app1,并且将 app2 渲染到页面上。
setState 执行后,调用链路简单来说是setState -> enqueueSetState -> scheduleWork -> requestWork -> 省略…
第一次调用 findHighestPriorityRoot
第一次调用是在创建 update 时的 requestCurrentTime 方法内,但第一次调用由于 firstScheduledRoot 好 lastScheduledRoot 都是 null,就等于不存在任何节点用于查找,所以这次调用没有任何意义。
第二次调用
requestWork 方法方法会调用 addRootToSchedule,调用参数为 app1Root(表示 app1 生成的 root,后面同理),调用后会将 firstScheduledRoot 和 lastScheduledRoot 这两个全局变量都赋值为 app1Root。
然后调用栈回到 requestWork 方法内,由于此时是「批量更新」(isBatchingUpdates === true),所以不会继续往下执行,而是中断,并等到该批次结尾再执行。
「该批次」可以理解为一次同步任务执行,上面例子就是
handleClick该方法执行完后。
所以接下来是调用 ReactDOM.render(<App2 />),render 方法的调用链路和 setState 差别不是很大,同样会调用 scheduleWork 并且之后就是一样的了。render -> updateContainer -> scheduleRootUpdate -> scheduleWork。
render 和 setState 一样也会创建 update,所以同样会调用 requestCurrentTime,所以也会调用 findHighestPriorityRoot 方法,此时由于 lastScheduledRoot 和 firstScheduledRoot 都已经被赋值为 app1Root 了,所以是可以进行查找的,但由于此时只存在 app1Root,所以肯定只能找到该节点,并且实际的该方法并不返回值,而是会将 nextFlushedRoot 全局变量置为找到的节点。
然后在 requestWork 方法内同样会调用 addRootToSchedule,不过这次和 setState 过程中调用时就不同了,此时lastScheduledRoot === firstScheduledRoot === app1Root,所以会走另外一个逻辑
1 | // root === app2Root、lastScheduledRoot === firstScheudledRoot === app1Root |
即将 app2Root 保存到 app1Root 上,然后将 lastScheduledRoot 覆盖为 app2Root,再将 app1Root 保存到 app2Root 上,用代码表示是这样的
1 | firstScheduledRoot === app1Root; |
这和我们之前自己实现 findHighestPriorityRoot 时使用的用例很类似,可以说就是在初始化这个链结构。
1 | const root1 = new Root(200); |
再次从 addRootToSchedule 方法回到 requestWork 中,此时会走非批量更新,即1
2
3
4
5
6
7
8
9
10
11
12// setState 过程中置为 true
if (isBatchingUpdates) {
// ReactDOM.render 过程中置为 true
if (isUnbatchingUpdates) {
// 所以会调用这里
// root === app2Root
nextFlushedRoot = root;
nextFlushedExpirationTime = Sync;
performWorkOnRoot(root, Sync, false);
}
return;
}
performWorkOnRoot 之后的调用链是 renderRoot,再之后的,也不会再调用 findHighestPriorityRoot 方法了。
第三次调用
app2 render 完成后,接下来会回到 app1 的更新,即调用 performSyncWork 方法,这是前面提到的「批处理结尾」时会调用的方法。
该方法就是调用 performWork(Sync, false),该方法内,先调用一次 findHighestPriorityRoot,此时仍然
1 | firstScheduledRoot === app1Root; |
app2Root 已经「完成工作」,或者说「已经无效」,所以需要被移除,我们前面也讲到如何从链中移除一个节点,所以 app1Root 就变成了 lastScheduledRoot,同时还是 firstScheduledRoot,并且 nextFlushedRoot 也置为了 app1Root。
然后再调用 performWork(nextFlushedRoot) 实现对 app1 的更新。
第四次调用
实际上,在 performWork(nextFlushedRoot) 下面,还会调用一次 findHighestPriorityRoot,目的是找到下一个需要更新的 root 进行更新。
1 | while (nextFlushedRoot !== null) { |
当然,这次调用时,app1Root 已经「无效」,所以被移除,链上不再存在节点,自然 nextFlushedRoot === null,从而中止了循环。
可能存在的疑问
1、为什么不直接调用两次 ReactDOM.render
1 | ReactDOM.render(<App1 />, document.getElementById('app1')); |
为什么这么写就不行?
因为 render 是非批量更新,即它会直接走完整个流程,如果想要出现链中有两个以上的节点,需要控制 addRootToSchedule 方法的调用顺序。
即,在第一个 app1 执行完 addRootToSchedule 方法后,需要中断当前 app1 的更新,开始下一个 app2 的更新。
所以,我们的实际用例可以改成先完成初始化,在点击按钮后,调用 app1 和 app2 的 setState。
还有一些遗漏,后面再补。