大纲

为什么说 Nodejs 是改变前端地位的发展呢。在 Nodejs 出现前,前端开发的工作范围被局限在浏览器环境,我们所有的代码,都只能运行在浏览器里面。
而 Nodejs 的出现打破了这个限制。
Nodejs 是什么
而 Nodejs 简单来说是让 js 代码能够直接在操作系统上运行的一个软件。
之前我们想测试一段 js 代码执行的效果,只能先新建一个html文件,在文件内的<script>标签内写我们的代码,再使用浏览器打开这个html文件。
但是安装 Nodejs 后,我们可以直接新建一个js文件,使用 Nodejs 来执行这个js文件!
比如我对splice方法记不太清,想要验证下:1
2
3
4
5// spliceTest.js
var ary = ['a', 'b', 'c'];
var newAry = ary.splice(1);
console.log(ary);
console.log(newAry);
然后可以直接使用node命令来运行一个js文件:1
node spliceTest.js
然后就会在当前命令行窗口看到我们打印的结果!
或者可以直接输入node进入交互模式,在该模式下输入的代码都会作为js代码执行。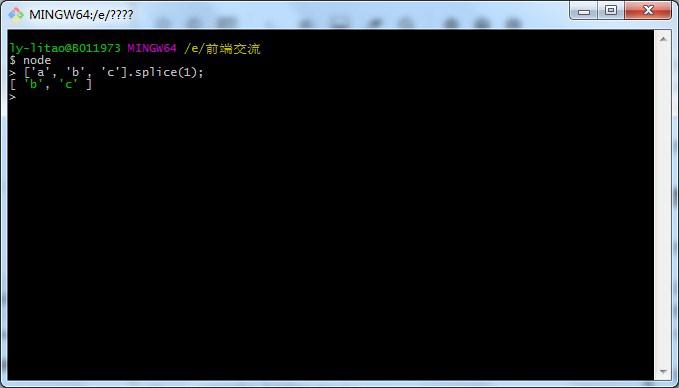
输入
.exit退出交互模式
如果熟悉 python 可能看到这里很眼熟,python 同样可以直接使用python xxx.py来执行一个py文件,也可以输入python进入交互模式直接写python代码。
Nodejs 和 python 我个人是认为可以算作同一类型的东西,同样是一个软件,能够解析各自的语法,实现很类似的功能。
Nodejs 和 JavaScript 有什么关系

之前一直都是说 “JavaScript”,其实并不是很严谨,严格来说 JavaScript 是 “ECMAScript 在浏览器环境的实现”,与之对应可以说,“Nodejs 是 ECMAScript 在服务器环境的实现”。
那ECMAScript又是什么东西?
其实ECMAScript就是语法,也可以说是标准。forEach()方法为什么能够遍历一个数组?这就是由ECMAScript规定的。
在浏览器环境的实现是什么意思呢?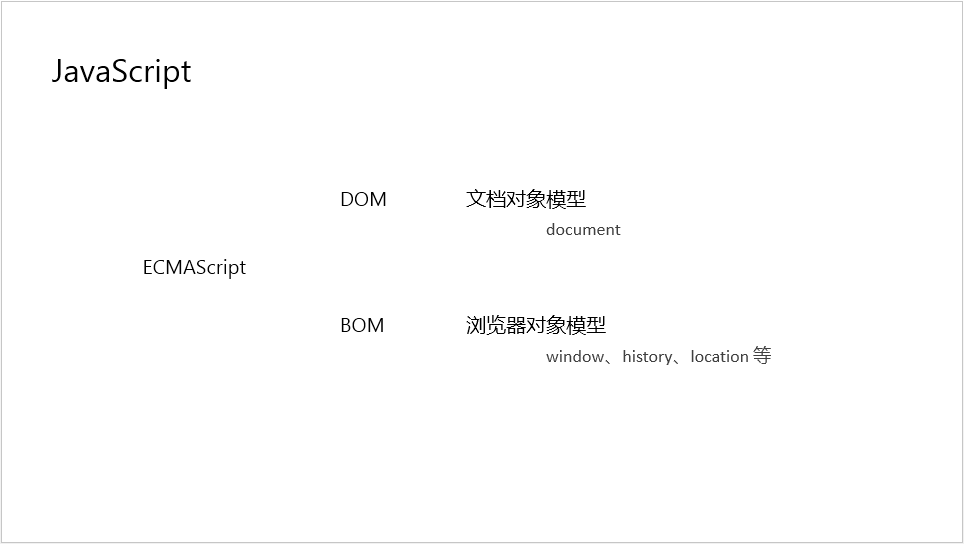
写过前端代码的都知道,在浏览器中有两个很重要的对象,DOM 和 BOM,实际上前端大部分工作,都是在操作 DOM,用ECMAScript语法操作 DOM。1
2var con = document.getElementById('container');
con.innerHTML = '<p>hello javascript</p>';
这么一段代码要从两个方面来看。
第一,语法,为什么是var而不是其他的关键字声明一个变量,这就是ECMAScript规定的。
第二,DOM,document是什么?这个在ECMAScript里面并没有,所以不是语法的东西,那就是浏览器给我们的。
与之对应,在服务器环境的实现就是指用ECMAScript语法,来操作服务器给我们的东西。而服务器给了我们什么呢?

很多很多的东西,fs、http、event 等等,具体的可以查看 node 文档。
下面代码是fs的作用。1
2// demo.txt
hello nodejs
1 | // index.js |
require方法不存在ECMAScript语法标准内,所以可以知道这是Nodejs给我们的东西。
使用node index.js可以看到输出1
hello nodejs
构建工具(实战
终于讲到能够实际使用的东西了。举个栗子,在做前端页面时,header 和 footer 往往是相同的,我们有index.html、login.html、register.html、detail.html等等文件,这些文件都需要 header 和 footer,在每个html文件内复制一份吗,当然可以。
“改一下 header 的结构”。??!!!修改好一份,再一个一个替换其他页面,或者使用编辑器的批量替换功能。
但是还有更简单的方式,就是“构建工具”。我可以开发出一个工具,输入一行代码,就自动帮我把header.html和footer.html的内容插入到index.html这些文件的指定位置。
目录结构
是的,使用 js,更严谨的说是 nodejs。目录结构是这样的:1
2
3
4
5tool.js
template
├── footer.html
├── header.html
└── index.html
1 | // template/header.html |
1 | // template/footer.html |
1 | // template/index.html |
可以看到,我在index.html文件内写了{header}和{footer},这是用来告诉我们的工具,把header.html文件内容放到{header},把footer.html文件内容放到{footer}。
获取 index.html 文件内容
OK,那开始我们工具的 js 代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14// tool.js
// 从 nodejs 中拿到 fs 这个对象,暂时只要知道 require 可以拿到 nodejs 给的对象就行。
var fs = require('fs');
// 调用 fs 对象上的 readFile 方法
// 这个方法能够获取到指定文件的内容
fs.readFile('./template/index.html', 'utf8', function (err, res) {
// 如果读取文件发生错误,打印这个错误
if(err) {
console.log(err);
}else {
// 如果没发生错误,就是读取成功,打印看看内容是什么
console.log(res);
}
})
OK,这是第一步,可以使用node命令看看有什么结果。1
node tool.js
正常情况下,会输出index.html的内容。知道了文件内容,就可以知道哪里要插入其他文件。
我们约定,
{xxx}形式的文本会被解析,xxx 是文件名,只支持英文字母。我们会把xxx.html文件的内容替换{xxx}。
提取插入的文件名
按照约定,也可以说是规则吧,我们从index.html文件内使用正则表达式分析出要插入什么文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// tool.js
// 从 nodejs 中拿到 fs 这个对象,暂时只要知道 require 可以拿到 nodejs 给的对象就行。
var fs = require('fs');
// 调用 fs 对象上的 readFile 方法
// 这个方法能够获取到指定文件的内容
fs.readFile('./template/index.html', 'utf8', function (err, res) {
// 如果读取文件发生错误,打印这个错误
if(err) {
console.log(err);
}else {
// 如果没发生错误,就是读取成功,打印看看内容是什么
// console.log(res);
// 二、提取插入的文件名
// match() 是字符串方法,传入正则表达式,返回数组
var files = res.match(/\{[a-z]+\}/g);
console.log(files);
}
})
/\{[a-z]+\}/g是一个正则表达式,能够匹配到{abcd}这种形式的字符串。这些是属于语法,也就是ECMAScript的范畴。暂时不用去了解具体原理,知道这样写可以提取出我们想要的内容就可以。
正常情况会打印1
[ '{header}', '{footer}' ]
获取指定文件名的内容
OK,既然知道了文件名,那就可以和上面一样使用fs.readFile方法获取到文件内容。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// tool.js
// 从 nodejs 中拿到 fs 这个对象,暂时只要知道 require 可以拿到 nodejs 给的对象就行。
var fs = require('fs');
// 一、调用 fs 对象上的 readFile 方法
// 这个方法能够获取到指定文件的内容
fs.readFile('./template/index.html', 'utf8', function (err, res) {
if(err) {
// 如果读取文件过程中发生错误,就打印错误
console.log(err);
} else {
// 不然就是读取成功
// console.log(res);
// 二、提取插入的文件名
var files = res.match(/\{[a-z]+\}/g);
console.log(files);
// 三、遍历 files 数组,获取每个文件的内容
files.forEach(function(file) {
// file 是 {header} 形式的,我们要获取到内部的 header
let fileName = file.match(/[a-z]+/g)[0];
fs.readFile('./template/'+fileName+'.html', 'utf8', function (err, res) {
if(err) {
console.log(err);
} else {
console.log(res)
}
})
})
}
})
/[a-z]+/g会提取出所有的连续的英文字母。所以对{header}可以得到header,对{footer}可以得到footer。
再次打印看看,可以看到输出了header.html和footer.html文件内容。
文件内容替换占位符
这是最后一步,既然获取到了文件内容,就可以把文件内容替换掉我们自己约定的{xxx}就好了。
不过在这之前需要修改一个地方,我们总共调用了两次fs.readFile方法是吧,所以我们有了两个res变量,这就导致了我们第二个覆盖了第一个,所以我们要把第一个保存了我们index.html文件内容的变量res起另外一个名字。
在第二步前面,我们这样做:1
2
3
4
5// tool.js
// ...
var content = res;
var files = res.match(/\{[a-z]+\}/g);
// ...
OK,修改好之后继续我们的替换。1
2
3
4
5
6
7
8
9
10
11
12fs.readFile('./template/'+fileName+'.html', 'utf8', function (err, res) {
if(err) {
console.log(err);
} else {
// console.log(res)
// 返回一个正则表达式
var regexp = new RegExp(file);
// 使用文件内容替换{xxx}这样的字符串。
content = content.replace(regexp, res);
}
console.log(content)
})
然后打印看看,可以看到打印了两次,第一次是将{header}替换掉了,第二次是将footer替换掉了。
生成文件
虽然替换成功了,但是在template文件夹内的文件并没有发生改变,因为我们并没有将我们得到的结果写入到文件中,所以我们最后的步骤就是写入文件。最终代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44// tool.js
// 从 nodejs 中拿到 fs 这个对象,暂时只要知道 require 可以拿到 nodejs 给的对象就行。
var fs = require('fs');
// 一、调用 fs 对象上的 readFile 方法
// 这个方法能够获取到指定文件的内容
fs.readFile('./template/index.html', 'utf8', function (err, res) {
if(err) {
// 如果读取文件过程中发生错误,就打印错误
console.log(err);
} else {
// 不然就是读取成功
// console.log(res);
// 二、提取插入的文件名
var content = res;
var files = res.match(/\{[a-z]+\}/g);
console.log(files);
// 三、遍历 files 数组,获取每个文件的内容
files.forEach(function(file) {
// file 是 {header} 形式的,我们要获取到内部的 header
let fileName = file.match(/[a-z]+/g)[0];
fs.readFile('./template/'+fileName+'.html', 'utf8', function (err, res) {
if(err) {
console.log(err);
} else {
// console.log(res)
// 返回一个正则表达式
var regexp = new RegExp(file);
// 使用文件内容替换{xxx}这样的字符串。
content = content.replace(regexp, res);
}
// console.log(content)
// 调用 fs 对象上的 writeFile 方法,第一个参数是要生成的文件名,第二个是要写入的内容,第三个是回调函数
fs.writeFile('index.html', content, function (err) {
if(err) {
console.log(err);
} else {
console.log('写入成功')
}
})
})
})
}
})
我们运行该文件,会打印两次写入成功,打开tool.js文件所在文件夹,会看到一个index.html文件,内容正是我们想要的。
我们修改template/footer.html文件内容,再次运行node tool.js,再看看和tool.js同目录下(非template目录)的index.html文件内容是不是也改变了?
实际使用中发现有时候生成的
index.html文件内容不对,这是由于异步操作导致的,下次具体来讲什么是异步。
模块与模块化
在写构建工具的时候,我们所有的操作,都是基于 fs 这个对象。1
var fs = require('fs');
require是 nodejs 自带的全局函数,用来“导入”模块。可以理解成在 nodejs 这个软件的目录下,有一个fs.js文件,这个文件定义了一个fs对象,这个对象上有很多操作文件的方法。我们使用require可以把这个文件的内容添加到当前的文件,就可以使用另一个文件的变量了。
还是举个栗子。1
2
3
4// sum.js
var add = function (num1, num2) {
return num1 + num2;
}
我写了这样一个文件,里面定义了一个add函数,作用是返回传过来的第一个和第二个参数的和。1
2
3
4
5
6
7
8
9
10
11
12
13// index.js
var fs = require('fs');
fs.readFile('./sum.js', 'utf8', function (err, res) {
if(err) {
console.log(err);
} else {
eval(res);
// 现在就可以使用 add 函数了
var result = add(3, 5);
console.log(result);
}
})
使用node index.js运行,可以看到打印了8。
这个栗子是想说明,基于 fs 模块,我们是可以获取到其他文件的内容,所以可以把代码根据功能来进行划分,算法归到一个文件夹,加法一个 js 文件,减法一个 js 文件,要用什么算法就导入什么算法,要对算法进行修改只要找到算法这个文件夹,找到对应的 js 文件进行修改就好了。
所以模块可以方便代码的管理与维护。
当然我们不可能像这个例子中这样获取另一个文件的内容,node 不仅提供了require导入,也提供了module.exports导出,所以上面的例子使用真正的“模块化机制”应该这样写:1
2
3
4
5// sum.js
var add = function (num1, num2) {
return num1 + num2;
}
module.exports.add = add;
1 | // index.js |
很方便的获取另外一个文件定义好的方法。
打包
之前说到,require是 nodejs 提供的函数,那是不是意味着在浏览器里面就不能用了,“是的,没错”。
还是拿上面的例子,我不能在index.html文件内写script标签引入index.js文件,浏览器会报错,因为根本不存在require()这个函数。
所以我们需要自定义一个require()函数,定义了require()函数浏览器就不会报错了。
当然自己写的话还要处理module.exports和依赖关系,所以使用别人写好的工具,比如webpack。
使用 webpack 打包
webpack 就和我们之前自己写的构建工具一样,在命令行里面输入一行代码,就可以得到新的文件。
先全局安装webpack:1
npm i -g webpack
然后使用1
webpack ./index.js common.js
这行代码表示,我要打包index.js文件,生成一个common.js文件。运行后在当前目录就会生成common.js文件,在index.html中引入这个新生成的common.js文件,可以在浏览器控制台看到输出了8!
感兴趣可以看看这个
common.js是定义了一个怎么样的require()函数。
这样就好了,我们可以把项目的代码进行组织,最后生成一个文件。
比如我们开发时使用的接口和正式上线的接口不一样,有两种做法
- 在
html文件引入多个 js 文件。 - 将多个 js 文件打包,
html只引入一个生成的 js 文件。
很明显引入多个 js 文件会影响网页访问速度,所以最好还是打包成一个文件,而且按照功能来组织文件也是很方便维护的,轮播图功能在一个文件、获取数据接口在一个文件、无限加载功能在一个文件。
当然如果每次修改代码都要手动执行一次webpack ./index.js common.js肯定也不行,所以这也是已经有解决办法了,只要再增加另一个模块webapck-dev-server即可。实现修改代码实时看到效果。
npm
从上面的例子中,我们又发现了一个新东西1
npm i -g webpack
这表示从 npmjs.com 下载了一个模块,这个模块就是很多 js 文件组成的,而且这个模块给出了一个webpack命令可以在命令行窗口中使用。
这就属于命令行工具的开发了,我们之前的构建工具也是可以做成像这样有自己的专属命令的形式。
感兴趣可以查看 Node.js 命令行程序开发教程
总结
nodejs 给了前端开发人员更多的能力,不再局限在浏览器中,我们可以写工具、写后端程序、写服务器运维脚本、爬虫甚至移动端应用等等。可以说,只要想做,用 js,或者说用 ECMAScript 都能够做到。